
판다스를 쓰다 보면 속도가 중요해질 타이밍이 종종 온다. 이 블로그를 통틀어서 몇 번이나 강조하지만, 데이터를 분석하는 입장에서는 데이터를 이것 저것 수정해보면서 여러 방법으로 돌려보는 것이 굉장히 중요하다. 하지만 이럴 때마다 비효율적인 방법을 사용해서 코드 하나 실행하는 데 몇 분, 심하면 한 시간이 넘게 이나 걸린다는 것은 재앙에 가깝다.
나 역시 처음 데이터 분석을 시작할 때, 10만 개짜리 데이터를 무작정 for 반복문을 사용해서 일일히 계산하던 삽질을 한 적이 있었다. 계산 시간을 줄여보려고 데이터를 3개로 쪼개어 컴퓨터 3대로 동시에 코드를 돌렸음에도 불구하고 결과값 하나를 보려고 3시간을 기다렸던 기억이 난다. 아침에 출근하자마자 코드를 돌려놓고 점심 먹고 와서야 겨우 완성이 됐을 정도로 고생을 했었는데, 지금 와서는 pandas 최적화로 같은 작업이 1분 내에 완료되는 것을 보면 참 감개무량하다.
이와 같이 pandas를 최적화하는 것이 왜 중요한지에 대해서는 이전 글에 자세히 써두었으니 해당 내용을 참고하면 된다. 특히 이번에 다룰 내용은 해당 글의 내용을 이해하지 못하면 소용 없으므로, 만약 내용이 어렵다면 다시 한 번 읽어보고 오길 바란다.
이번 글에서는 벡터 연산에 대해서 조금 더 다룬다. 사실 저번 글에서 내용은 거의 다 다루었고, 프로그래밍에 센스가 있는 사람이라면 해당 내용만으로도 충분히 잘 응용할 수 있다. 때문에 이번 글에서는 간단하게 벡터 연산을 활용하는 법에 대해서 알아볼 것이다.
0. 데이터 불러오기
이번 시간에 활용할 데이터는 저번 글과 같은 new_york_hotels.csv를 사용한다. 다운로드 및 임포트 방법 역시 저번 글에 나타나 있으므로 참고하면 된다.
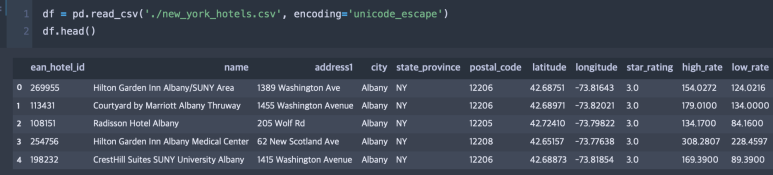
데이터를 불러오고, df라는 이름의 데이터프레임을 선언하고 여기에 저장한다.
1. 벡터 연산 기본
벡터화의 개념은 어려운 것이 아니다. 그냥 계산을 하나씩 하지 말고 통째로 해 버리자는 것일 뿐이다. 예컨대 위 df에서 high_rate라는 칼럼의 값을 전부 다 2배로 만드려면 어떻게 해야 할까?
for 반복문을 사용하면 다음과 같다.
df.loc[row, ‘high_rate’] = df.loc[row, ‘high_rate’] * 2
row = row + 1
눈치챘겠지만 이는 필자가 이전에 했던 것과 같이 비효율적인 방법이다. for 반복문을 사용하면 데이터프레임의 처음부터 끝까지 훑어야 하므로 그만큼 컴퓨팅 자원을 더 많이 소모하게 된다. 예제 데이터는 얼마 되지 않아 4-5초만에 금방 끝나는 것을 볼 수 있지만, 데이터의 양이 1만 개 정도만 넘어가도 끔찍하게 느려지는 모습을 확인할 수 있다.
가장 깔끔한 방법은 바로 위와 같이 df의 ‘high_rate’ 칼럼에(pandas에서는 ‘series’라 부른다) 바로 계산을 때려버리는 것이다. 이렇게 하면 데이터프레임의 내의 각 데이터에 직접 하나하나 접근할 필요 없이 한 번에 계산을 진행해버리므로 순식간에 작업이 종료되는 모습을 볼 수 있다.
저번에도 언급했지만 다들 위와 같은 계산 방법에 대해서는 pandas를 처음 배울 때 한 번쯤 접해보았을 것이다. 교재 등에서는 아무래도 위와 같은 계산법이 초반 부분에 나타나므로 잘 언급하지 않는 모양이지만, 이렇게 한 번에 계산을 하도록 만드는 것이 벡터 연산, 또는 벡터화 연산이라고 한다.
여담으로, pandas에서는 수치형 자료만 벡터 연산이 가능한 것은 아니다. 텍스트 등의 오브젝트 데이터도 형식과 문법만 잘 맞추어 준다면 다음과 같이 벡터 연산이 가능하다.

df[‘name’] series(칼럼)의 모든 값 앞에 ‘Hotel Name : ‘이라는 값을 벡터 연산으로 붙여주었다
2. 벡터 연산에서 주의하여야 할 점
벡터 연산을 진행할 때 주의해야할 점은 데이터의 포맷이 맞아야 한다는 것이다. 다음을 보자.
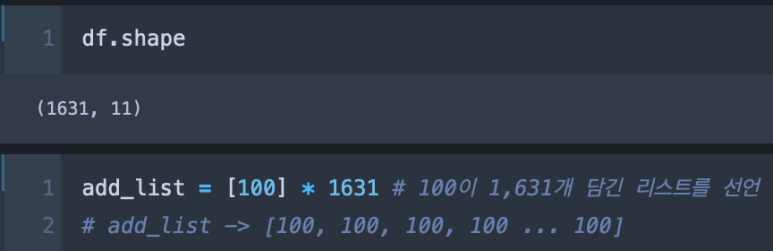
df.shape로 df의 형태를 확인해보니 행이 1,631개, 칼럼이 11개로 나타난다.
계산을 적용해주기 위해 add_list라는 100이라는 값이 담긴 리스트를 선언하고, 1,631개의 길이가 되도록 1,631를 곱해준다. 그러면 add_list는 [100, 100, 100, 100 … 100]과 같이 100이 1,631개 담긴 리스트가 된다.
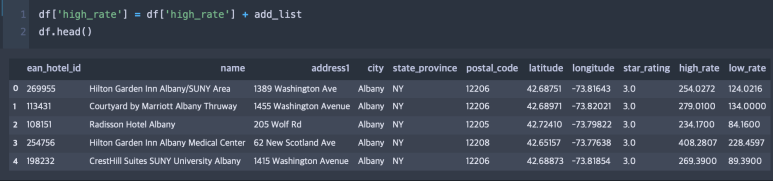
이를 df[‘high_rate’] 시리즈(칼럼)에 더해주었더니 high_rate의 값이 전부 100씩 더해진 것을 확인할 수 있다. 당연하지만 이 연산은
와 동일한 연산이다.
반면 다음과 같은 코드를 실행하면 에러가 난다.
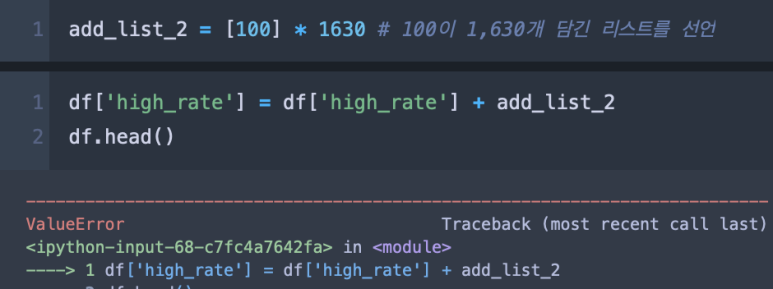
이유는 짐작하겠지만 df의 row 길이는 1,631개인데 길이 1,630짜리 데이터와 연산을 시도했기 때문이다.

위 에러 메지시를 보듯 길이 1,631개짜리와 길이 1,630개짜리는 계산할 수 없다고 한다. 즉 시리즈 간 벡터 연산을 시도하려면 기본적인 길이 포맷은 맞추어 주어야 한다.
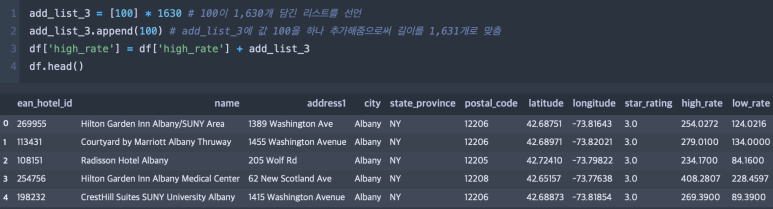
위 예제와 같이 100값 하나를 추가해주어서 길이를 1,631개로 만들어주면 정상적으로 작동하는 것을 확인할 수 있다.
그러나 당연하지만 길이만 맞다고 해서 전부 다 벡터 연산이 가능한 것은 아니다.
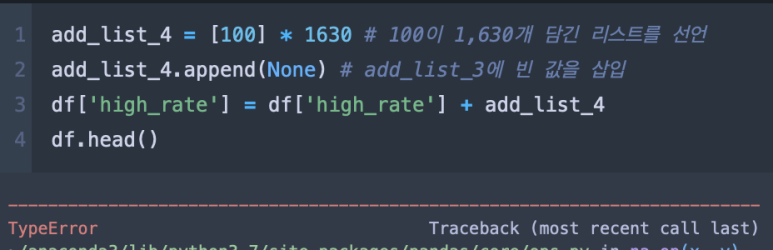
위 예제를 보자. 위 예제는 add_list_4에 100이라는 값 1,630개를 만들고, 거기에 길이를 1,631개로 맞추기 위해 데이터를 하나 추가해주었다. 이로써 길이는 1,631개지만 문제는 그 데이터가 None값이라는 것이다. 결과는 위에서 보듯 TypeError가 나타난다.
즉 벡터 연산을 진행하려면 데이터의 길이와 형식이 적절하게 맞아야 한다는 것이다.
다시 말해 첫째로 길이가 같든지 또는 df[‘high_rate’] * 2와 같이 하나의 연산을 전체에 적용시킬 수 있는(브로드캐스팅이라 한다) 연산이어야 한다는 것이고, 두 번째로 숫자는 숫자값끼리, 텍스트는 텍스트끼리와 같이 서로 간에 계산할 수 있는 값이어야 한다는 것이다.
데이터의 형식을 맞춰주는 문제는 글만 읽었을 때는 너무나도 당연한 얘기처럼 들린다. ‘당연히 숫자는 숫자 끼리만 계산할 수 있으니 데이터를 맞춰주면 되는 문제 아닌가??’라고 생각할 수 있다.
물론 그렇다.
하지만 이 문제는 장담컨대 실무에서 가장 많이 발생하는 문제 중 하나이다. 실제 데이터 분석을 하다 보면 데이터가 정제되지 않은 경우가 너무나도 많고, 실수로 잘못 기입된 데이터(human error)나 결측치 등으로 인해 데이터의 중간에 값이 이상하게 꼬여 있는 경우가 많기 때문이다. 데이터가 10만 건, 100만 건 등과 같이 사람이 눈으로 일일히 다 확인할 수 없는 데이터의 경우 문제가 더 복잡해진다. 이런 경우 EDA나 적절한 인사이트를 활용하여 결측치를 제거하거나 데이터 타입을 맞춰주어야 한다.
3. 조건부 벡터 연산
앞서 말했듯 기본적인 벡터 연산은 다음과 같은 형식이다
이런 형식의 벡터화와 벡터 연산은 꽤 직관적이고 이해하기도 쉽지만, 문제는 이런 단순한 계산은 실제로는 거의 쓰이지 않는다는 점이다. 실무에서는 특정 조건을 만족하는 일부 데이터만 뽑아내서, 그 데이터에만 적절한 연산을 취하는 등의 계산을 진행한다. 이럴 때 사용하는 것이 바로 조건부 벡터 연산이다.
pandas dataframe에서 조건 추출하면 가장 먼저 떠오르는 것은 바로 .loc 인덱서이다. 때문에 조건부 벡터 연산 역시 .loc 인덱서를 사용하여 진행한다.
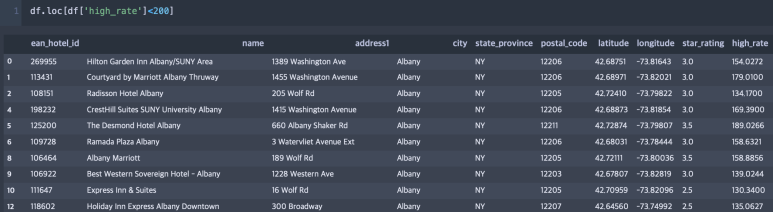
예컨대 df[‘high_rate’] 시리즈 중, 값이 200보다 작은 모든 데이터에 값에 +200을 해본다고 생각해보자. loc 메서드를 활용하여 df[‘high_rate’] 시리즈 중 200보다 작은 값을 추출하는 방법은 다음과 같다.
그러면 다음과 같은 결과가 나온다.
우리는 여기서 ‘high_rate’의 값만 보기를 원하므로, loc 메서드에 칼럼 인덱스를 추가로 넣어준다.
.loc 메서드에 인자를 2개 넣으면 첫 번째 인자는 행, 두 번째 인자는 칼럼값을 받는다. 그러면 다음과 같이 시리즈 형태로 데이터가 반환된다.
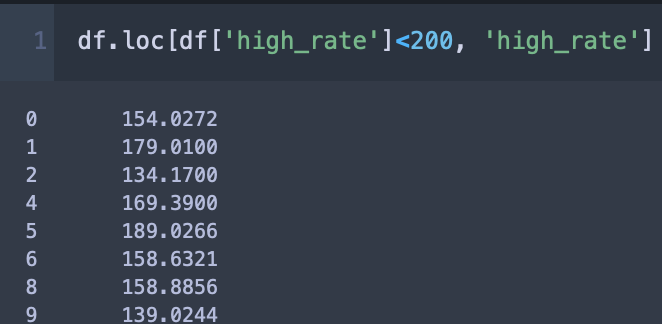
데이터가 시리즈 형태로 받아져왔다는 것은 곧 벡터 연산을 진행할 수 있다는 뜻이다.
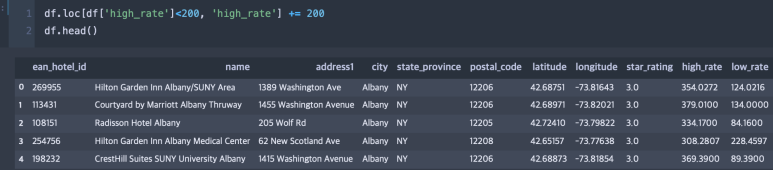
그러면 위와 같이 조건부 벡터 연산이 무리없이 진행되는 모습을 볼 수 있다.
python 문법에 익숙하지 않은 사람들을 위해 잠깐 설명하자면, +=는 해당 데이터에 바로 더하라는 의미다. 예컨대 a = a+b와 같은 문장은 a += b와 같이 줄여 쓸 수 있는 것이다. += 말고도 -= 등과 같은 것들이 있으며, 궁금하면 구글에 ‘복합 연산자’를 검색해보자.
조건부 벡터 연산은 .loc 메서드에서 반환되는 시리즈 값을 통해 이루어지므로, .loc에 여러 조건문을 동시에 넣어 다중 조건부 벡터 연산을 진행할 수도 있다.
예컨대 위의 문장은 df에서 high_rate 칼럼의 값이 200보다 작으면서 동시에 city 칼럼의 값이 ‘Albany’인 값인 데이터들의 ‘high_rate’ 값만 추출한 것이며, 이런 식으로 활용하면 다중 벡터 연산을 진행할 수 있다.
4. 복합 벡터 연산(고급)
사실 3번까지의 방법만 잘 응용한다면 상당히 많은 문제를 해결할 수 있다. 그러나 실무에서는 높은 수준의 조건부 연산이 진행되는 경우가 종종 발생하는데, 이 때 loc 메서드를 활용하여 조건을 추출하기에는 한계가 있다. 특히 데이터프레임 에서 조건을 추출할 때 외부의 if_else문이 들어가거나 할 때와 같은 경우들이다.
이런 경우는 벡터 연산을 한 번에 진행하기에는 다소 무리가 있으며, 억지로 진행한다 하더라도 코드가 굉장히 복잡해지기 때문에 추천하는 방법은 아니다.
복합 벡터 연산을 하는 데에 가장 좋은 방법은 해당 조건을 만족하는 데이터들의 인덱스 값만 구하는 것이다.
기본적인 원리는 간단하다.
우선, 계산을 적용할 데이터들에 대한 조건문을 작성해서 해당 데이터들을 추출한다. 이 경우 loc 메서드가 여러 번 중첩되어 사용될 수 있지만, 조건 추출에는 그다지 시간이 많이 걸리지 않으므로 큰 상관이 없다.
다음으로 추출한 조건문들에 대해서 인덱스 값만 추출해낸다. 어떤 조건 추출을 사용하든 loc 메서드를 사용해서 해당되는 데이터가 추출되었을 경우 dataframe 또는 series 데이터로 추출되었을 것이다. 즉 우리는 여기에 .index 속성을 사용하여 해당되는 데이터의 인덱스 값만을 확인해올 수 있다.
마지막으로 해당 전체 데이터프레임에 해당 인덱스 값들만을 대상으로 한 벡터 연산을 진행하면 된다.
글을 쭉 읽으봤다면 알겠지만 벡터 연산은 pandas 데이터 분석에서 초보인지 아닌지를 구분짓은 가장 중요한 것들 중 하나이다. 익숙해진다면 대부분의 경우에 벡터 연산을 활용하여 데이터 분석에 걸리는 시간을 압도적으로 줄일 수 있기 때문에, pandas를 활용하여 데이터 분석을 하려는 사람이라면 꼭 이해하고 넘어갈 것을 강력하게 추천한다.
#벡터화, #벡터 연산, #데이터분석, #빅데이터, #pandas, #dataframe, #판다스최적화, #biodata, #문과코딩
출처 : https://blog.naver.com/draco6/221680932777

![[Pandas] Dataframe의 행을 반복하는 방법 (iterrows, itertuples, index, loc, iloc)](https://blog.kakaocdn.net/dn/bGI3kB/btrG7X9YLX1/k6iQYQYl9pt2RvgzX1cuV0/img.png)